|
I'm a 1st year Ph.D student at HKU IDS advised by Prof. Yi Ma. Before that, I obtained B.Eng. in Computer Science (Honor) from ShanghaiTech Unviersity. I started my research journey at Berkeley also with Yi. I am from Suzhou and love to season my dishes with sweet . |


|
|
I am generally interested in data, architecture, training, and understanding of foundation models. Recently, I bet on training (M)LLM with reinforcement learning, especially on its empirical understanding. Prior to this, I did some representation learning and interpretability research during my visit at Berkeley. |
|
Aug 2025: Check out the new book and cute chatbots~ Apr 2025: Our paper SFTvsRL is accepted by ICML~ Fall 2024: I joined HKU IDS~ Jan 2024: Our paper CPP was accepted by ICLR 2024! See you in Austria. Nov 2023: Our paper CRATE-Segmentation was accepted by CPAL 2024 and NeurIPS 2023 XAI Workshop, both as Oral! Note: see here for what's CPAL. Sep 2023: Our paper CRATE(white-box transformer) was accepted by NeurIPS 2023! May 2023: Gonna leave lovely Berkeley (as well as U.S.), finishing 7 tech courses and a few interesting research projects. |
|
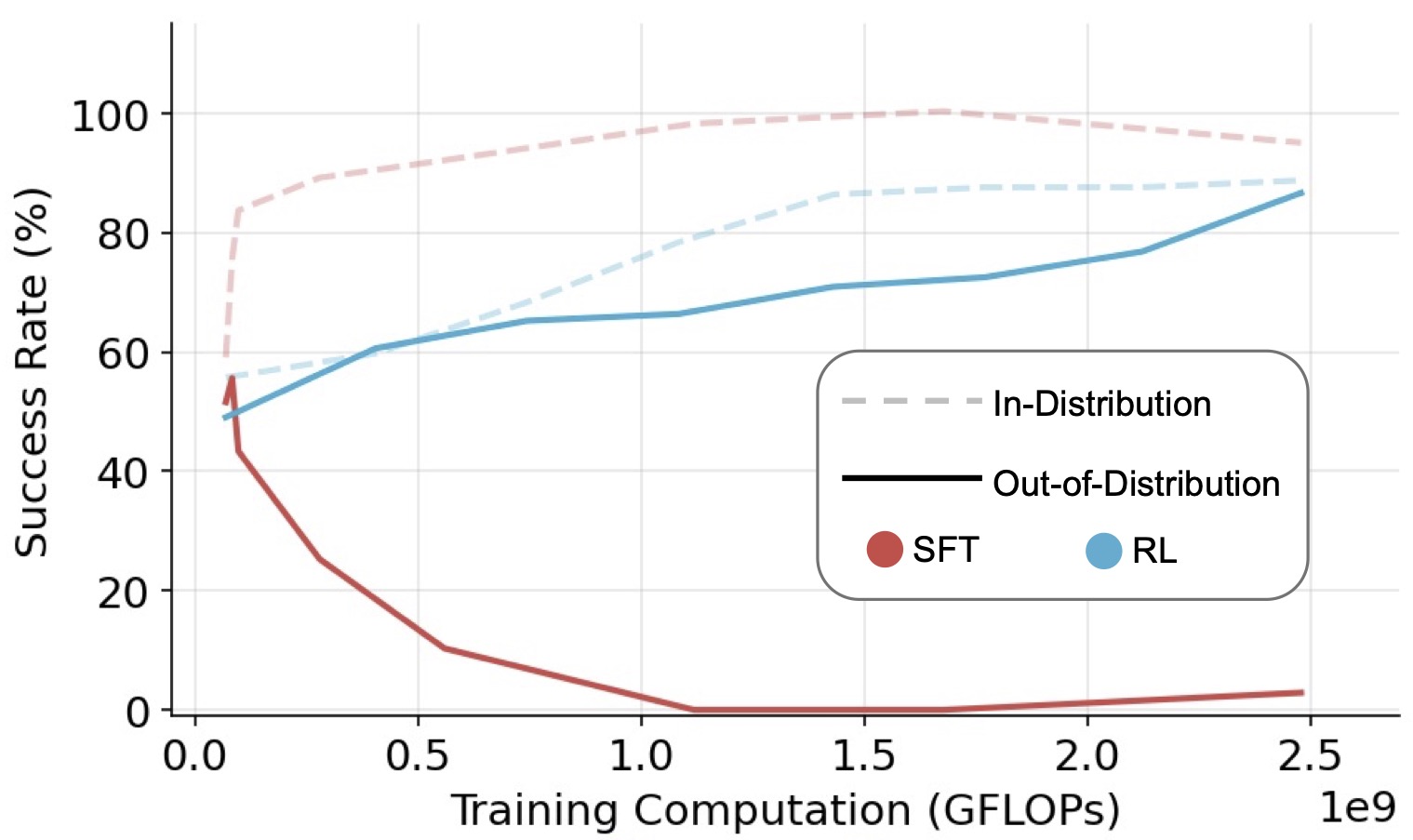
Tianzhe Chu*, Yuexiang Zhai*, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, Yi Ma ICML 2025 project page / code / arxiv Title is all we need. |

|
Chun-Hsiao Yeh*, Chenyu Wang*, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, Yi Ma Preprint project page / bench / arxiv This benchmark aims to evaluate multi-view awareness of MLLMs. |

|
Yaodong Yu*, Tianzhe Chu*, Shengbang Tong, Ziyang Wu, Druv Pai, Sam Buchanan, Yi Ma Accepted by CPAL 2024(Oral), NeurIPS 2023 XAI Workshop(Oral)(4 out of 59 accepted papers) demo / project page / code / arxiv The white-box transformer leads to the emergence of segmentation properties in the network's self-attention maps, solely through a minimalistic supervised training recipe. |

|
Tianzhe Chu*, Shengbang Tong*, Tianjiao Ding*, Xili Dai, Benjamin D. Haeffele, René Vidal, Yi Ma Accepted by ICLR 2024 code / arxiv This paper proposes a novel image clustering pipeline that integrates pre-trained models and rate reduction, enhancing clustering accuracy and introducing an effective self-labeling algorithm for unlabeled datasets at scale. |
|
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Benjamin D. Haeffele, Yi Ma Accepted by NeurIPS 2023 code / arxiv We develop white-box transformer-like deep network architectures which are mathematically interpretable and achieve performance very close to ViT. |

|
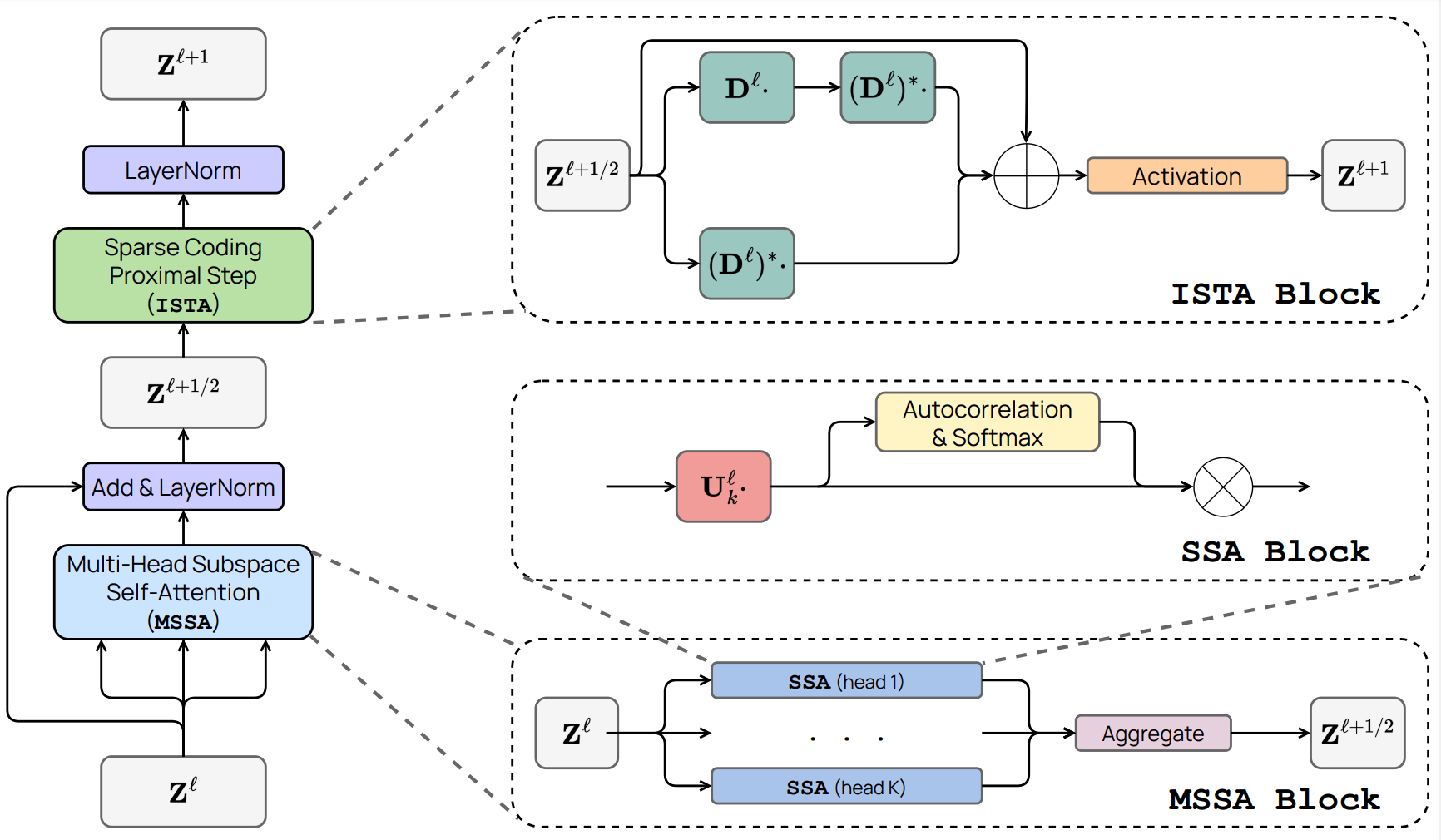
Yaodong Yu, Sam Buchanan, Druv Pai, Tianzhe Chu, Ziyang Wu, Shengbang Tong, Hao Bai, Yuexiang Zhai, Benjamin D. Haeffele, Yi Ma Accepted by JMLR project page / code / arxiv We propose CRATE(comprehensive version), a "white-box" transformer neural network architecture with strong performance at scale. "White-box" means we derive each layer of CRATE from first principles, from the perspective of compressing the data distribution with respect to a simple, local model. CRATE has been extended to MAE, DINO, BERT, and more transformer-based frameworks. |
|
TA: DATA8014 Deep Representation Learning (2025 Fall) Reviewer: ICLR 2025, ICML 2025, NeurIPS 2025 Co-organizing: Lap-Chee Hiking Club, ALICE Seminar |
|
If you need some academic guidance / talk about my research / chat about AI, shoot an email to me. I occasionally share photos here. |